2022. 3. 19. 14:55ㆍ괴발개발 이야기
환경을 오빠가 구성해보기로 했으므로 나는 내 아이디어를 실현시키기 위해
필요한 기능들을 예제처럼 구현해보기로 하였다.
바로 node 로 크롤링 해보자.
crawler 를 이용해 원하는 사이트에 접속하는것은 워낙 쉽기도 하므로 실제 원하는 값을 크롤링 하는것만
기록해보기로 한다.
우선 구글링으로 크롤링을 위한 자료를 검색후에 예제를 그대로 해보기로 하였다.
[네이버 메인의 뉴스 언론사 리스트를 가져와보자!]
1. node에서 크롤링을 위한 crawler 모듈 설치하기
-> npm install crawler --save 실행.
2. 네이버 사이트에서 F12를 눌러 개발자 모드로 해당 화면의 html 소스를 봐보기
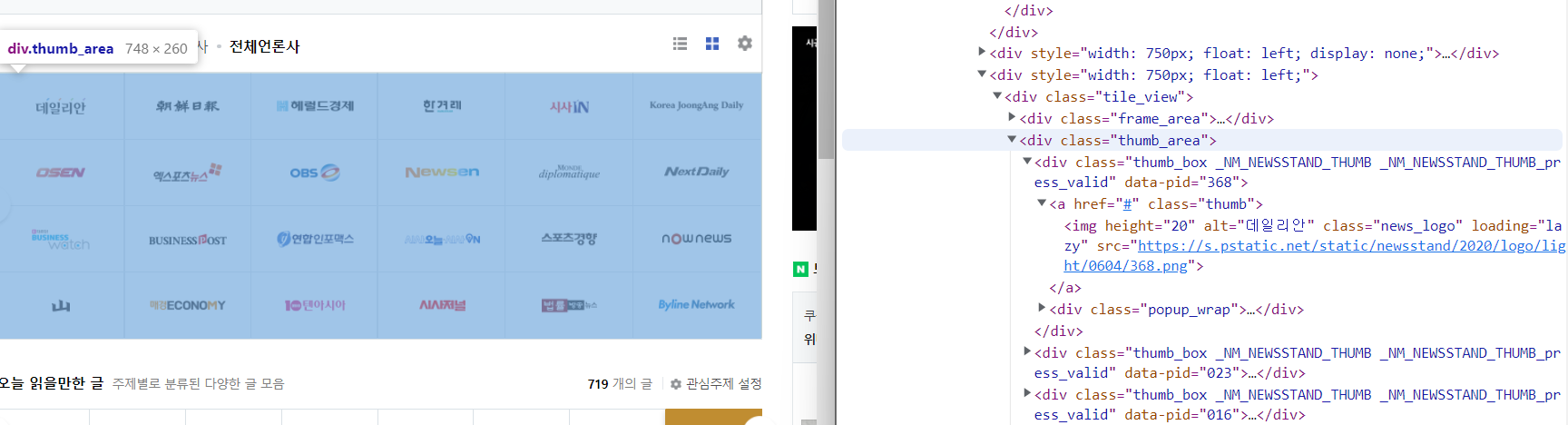
개발자 도구에서 해당 리스트가 있는 div를 찾아 해당 class 가 어떻게 정의되어있는지 확인하니
class = "thumb_area"로 정의되어 있었다.
그 및에 div class가 thumb_box_!@#$%로 언론사들이 리스트처럼 나열되어 있었다.
언론사들의 이름은 class = "thumb_box_"의 하위 a태그안의 img안에 alt안에 적혀있음을 확인하였다.
3. 자 그렇다면 소스를 그대로 가져와서 실습 해보자.
a. thumb_box안에 있는 모든 해당 리스트를 bodyList에 저장해주자.
-> const $bodyList = $("div.thumb_area").children("div.thumb_box");
b. 저장된 bodyList에서 나는 언론사 이름이 정의되어있는 alt의 값이 필요하므로 list 배열에 해당 alt값만 축출해보자.
-> let newList[];
$bodyList.each(function(i,elem){
newList[i] = $(this).find('a.thumb img').attr('alt');
});
c. console에 newList를 찍어주면 네이버 메인의 언론사 리스트들이 쫘악~ 출력됨을 확인.
오늘 끗.
'괴발개발 이야기' 카테고리의 다른 글
| [괴발개발]개발을 시작해보자! (0) | 2022.03.13 |
|---|---|
| [괴발개발]git을 그냥 써보자. (0) | 2021.09.06 |
| [괴발개발]시작해보자 (0) | 2021.09.06 |